
[Tech] Knowledge-as-Code
Benefits of statically typed functional programming? Wrong question.

“What are the benefits of X?” is a rather natural question to ask when you are curious about a subject. However, the response will be very different depending on who gives the answer.
Asking ”what are the benefits of a Formula 1 car?” would result in very different replies if you asked a race driver, farmer, carpenter, or a submarine captain.
I think a serious source of miscommunication could be eliminated if we spent a bit more time talking about the wanted end goal and try to find a non-fluffy answer. We as people have a tendency to assume everyone has the same goal or ”we are all farmers”.
This problem often comes up when discussing XDD techniques (DomainDrivenDesign DDD, TestDrivenDesign TDD, Type Driven Design TDD). These techniques focus on the how not the why – the engine, not the goal.
So I think a better question is:
What do we want to achieve?
Let’s start with tests and TDD (test-driven development). The “why question” in this case is “why do we write tests?”. A straightforward answer is “To make sure the program works”. However, what do we mean by “works”?
When programming, a developer creates a mental model of how the program should work and try to explain that to the computer via code. Another word for this mental model is domain knowledge. A program “works” if the developer has a correct understanding of the domain, and manages to capture that understanding in code.
How does this understanding of “working programs” == “encoded domain knowledge” play out in practice? It appears every time the program needs to be updated! In order to update the program while making sure that it still works, the developer doing the update must know how the program is supposed to behave. Often the code is not enough so they need to reverse-engineer the thought process, look up documentation or ask the original author (who hopefully remembers and is still reachable).
When programming, we want to capture knowledge in a way understandable for both the computer and humans, now and in the future.
Why do we want to capture knowledge?
* First and foremost to avoid vital knowledge to be lost. As time passes people will stop remembering and the organization will change. Old team members will pursue other projects and new members will join. When knowledge is captured and accessible for later use the organization will become much more resilient. The “old guard” that understands the hidden depths of the application is simply not needed (at least not for that reason). One thing is for certain; People won’t stay forever.
* If we make the computer understand the domain knowledge, we ensure that the knowledge we do have is enforced (“All cars should have four wheels”). The scope of most projects is too large to keep in human working memory at once, requiring assistance from the computer.
* New features should take current domain requirements into consideration. Often, new requirements will affect old ones – sometimes with unexpected consequences. It’s best to identify these unexpected or unwanted consequences early on, since fixing such issues tends to get more expensive over time.
* Knowledge of who can access what is extra important to enforce using the computer. We don’t want security risks where the application could leak information.
* Easy-to-access and explicit knowledge of how the system works makes onboarding new team members much easier.
* Make it clear what the organization knows and what it does not know. This can be vital for important business (and technical) decisions.
* Makes it possible or even easy to include business people in technical decisions – “Should all cars have exactly four wheels? If no, what is the difference between a car with two wheels and a motorcycle?”.
* Avoid bugs introduced when making a seemingly innocent change that violates an implicit invariant.
* Avoid having to spend time on “defensive programming”, where the programmer makes up for limited understanding with countermeasures such as wide-spread null checks, assertions sprinkled across the code, and similar. This behavior solidifies invariants across the entire code base, making it rigid to change.
All this fluff – What is knowledge then, more specifically?
On a 10 000 meter level: Information about the domain or problem that the current author has which affect their choices and the design of the code.
More concretely:
* What kind of inputs are valid/expected
* What can the output be?
* What can go wrong?
* When should this code be used? When should it not?
* Does running this code do anything but return a value? (Side effects)
* How do similar domain concepts differ? (A user with admin rights and an admin user)?
How is knowledge best captured?
Now you could say, but ”all code is knowledge, with an if-statement it is clear that the x variable needs to be smaller than 5!”. It’s true – all code tells the computer something – the question is which solution is the most scalable and friendly to both human and computer. When the program grows, and the “smaller than 5 check” moves to another function, file or module, this previously clear fact will be very difficult to spot.
Quick detour – ”X as Code”, X-as-C
In the last two decades, approaches like ”Configuration-as-Code” and ”Infrastructure-as-Code” have grown tremendously in popularity and made organizations much less reliant on a few individuals to set up a new server or application cluster. These approaches are often declarative, the focus of the reader/programmer is what you want to happen – not exactly how. You state, ”ssh should be configured” not ”>command1 -x; command2 -y -z; etc… ”
This invites people who are not experts in the given technology to participate and change the wanted end state without having to understand the nitty-gritty details. The knowledge that ”ssh should be configured” is stated explicitly once, leaving the details to be sorted out somewhere else.
More examples of this: Docker, Chef, Nix among many others.
So again, how is knowledge best captured in code?
To enable our human minds to grasp ever more complex domains, we want our knowledge to be encoded in a declarative and explicit manner. It’s best if this information is contained within a limited scope, rather than spread out across the program. This protects our knowledge from being lost due to code evolving over time.
And that leads us to the main event: Knowledge-as-Code.
Knowledge-as-Code
Knowledge-as-Code (or Know-as-C or ”no-ask”) is fully language- or platform-agnostic and states that knowledge should be:
* Declared once – enforced globally
* Complete
* Precise
* Symmetric
* Unobfuscated
Declared once – enforced globally
Using central and declarative syntax makes it possible for humans to understand and decode knowledge even if the code base is vast. It also makes it easier to review changes to the requirements. If the requirements are spread out across the codebase this is almost impossible to do, e.g. if an if-statement is changed from ”if noOfWheels < 5 then ..” to ”if noOfWheels < 6”, how do we know if this applies everywhere?
The declared domain rules should be enforced globally by the computer – humans are really bad at this and with a growing codebase it is practically impossible to do. By capturing the domain knowledge in a single spot, we make it possible to use a computer to enforce these rules.
A centrally declared requirement prohibits conflicting definitions, such as having both”if noOfWheels < 5 then return ValidCar” and ”if noOfWheels < 6 then ValidCar” in the same code base.
Complete
* All valid values should be representable.
If we want to allow numbers larger than 2^45 we should not use an Int32
* All known unknowns should be explicitly expressed
If a function can fail, the computer should force you to handle the failure case
Precise
* Only valid values should be representable.
If a function expects a positive integer, it should be impossible to send in a negative one
* No overlap
All possible values should be orthogonal with each other. Example: We cannot say that we have either a Int or a Float. Since all ints are included in the Float type.
Symmetric
* All knowledge should be available to both human and computer
Humans must understand the knowledge to make changes – the computer must understand the knowledge to be able to enforce the rules.
* All feedback should be available for both humans and computers.
When something goes wrong the computer should help the human to understand the issue.
Unobfuscated
* Use abstractions without knowledge loss.
If, in reality, you have a bird or a cat – do not hide it behind a IAnimal or similar. Better to abstract it to, in pseudo-code, ”Animal = Bird OR Cat”.
or
* Abstract using general, well-defined, non-domain concepts
Such as lists, Dictionary, Functor, Monad
Tools to write Know-as-C
Most statically typed languages are capable of capturing some information in a declarative manner in what I’ll loosely call ”types” below. There are other concepts that also declaratively capture knowledge but for now, we’ll use the term “types” as an umbrella term.
Since dynamically typed languages per definition do not have any way to enforce knowledge statically, nor in most cases encode it declaratively, I do not think they are a good option when trying to capture knowledge.
It is important to remember that the cost of encoding knowledge differs between languages and different points of cost and return exist depending on which team and which time frame the project operates under. However, encoding knowledge is vital if you want to know what you have built if you are building a long-lasting product, or where trust or security is important. That being said, the “bang for the buck” will differ greatly depending on which programming language is used.
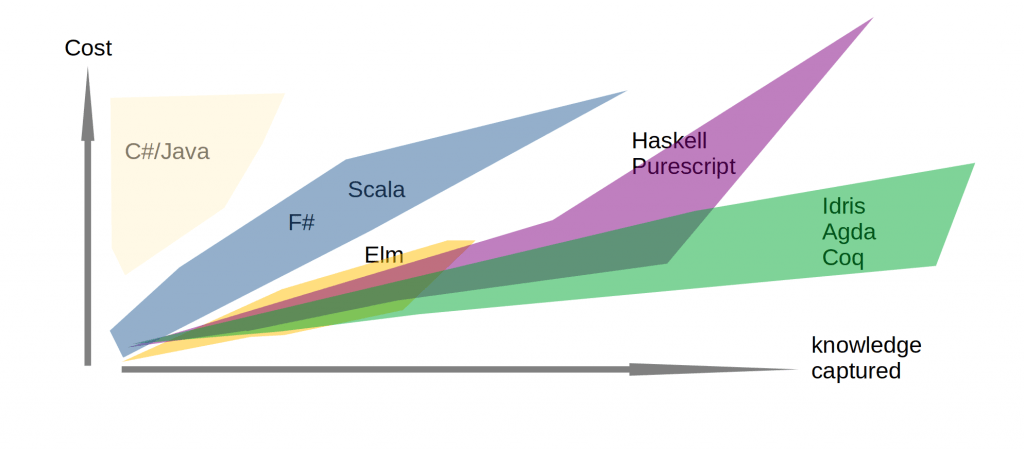
There are a bunch of more or less language-agnostic techniques that can be used as well. For example ”Ghosts of departed proofs”, “Type-driven-development”, “Parse don’t validate”, ”Dependent types” or “Doctests”. As it happens, what these have in common is that they all improve knowledge symmetry and help us reach the other Know-as-C goals.
In general, humans understand some formats and computers another, we want to fuse those so both parties are included – without sacrificing either party’s understanding.
For example:
| Human only | Both human and computer | Computer only domain |
| Comments Comment examples* Class names Function names Variable names Record field names ADT tags Value level understanding** | Types Function signatures | Machine code |
| Potentially false Room for interpretation Rot over time Victims of ”game of telephone” | ”Understood” by the computer Understandable by a human |
* as default in most languages
** in most languages
Special case
| Tests |
It cuts both ways
Many strong (and not so strong) compilers fail at informing humans of issues in a pedagogic manner. In other words, the compiler fails to ensure knowledge symmetry. This is a non-trivial problem to solve, and tends to be overlooked in many languages. In some cases, this even leads to a situation where programmers stop seeing the compiler as their assistant and start seeing it as their antagonist.
One example that actively tries to be better is Elm. Even if Elm’s approach is not perfect in all regards, the compiler goes a long way in giving human-readable, solution-oriented feedback. That being said, the complexity of the problem of good feedback increases with the competency of the language.
Could it be that this negligence towards the programmer is a contributing factor to hold languages such as Haskell back? A lot of angry and large error messages have a solution that can be described clearly by a human just in a few words ”That function is only partially applied” or ”The arguments is in the wrong order” or ”You forgot the do keyword”.
Haskell’s error messages very clearly describe what is wrong like “Size of sulfation plates prohibits needed chemical interaction” but often lacks the solution-oriented information “Time to change the battery”.
This is one instance where the programmer needs a lot of language-/compiler-specific knowledge which enables them to summarize the implicit information given by the compiler into actionable concepts.
Doctest, an example of giving the computer access to more knowledge
Docstrings are comments above functions briefly describing the function. They often contain one or more examples, showing what inputs lead to which outputs. This has multiple benefits, including giving the user of the function a quick way of understanding exactly what the function name or signature meant. Since this is knowledge not understood by the computer, the Know-as-C approach would be increasing type safety rather than adding human-only information using comments. Due to language limitations or other reasons that may not always be possible.
The drawbacks of examples in the docstrings are
* The computer does not have access to these examples and therefore does not check their validity
* A human will extrapolate the example, correctly or incorrectly and therefore expect a certain behavior
* No syntax or compiler check
If comments are necessary, this information asymmetry can be reduced using libraries such as “doctest”. Doctest is available in several languages. Using a doctest library, you give the compiler access to the doc-test examples and they will be checked during compile/testing. This means that all the benefits for the human stay intact, while we increase the amount of knowledge that can be computer verified.
Let us talk tests
* Are we writing tests to capture knowledge to future human readers?
Will they have practical access to that knowledge?
Could that knowledge be described in a more declarative and general way?
* Are we writing tests to make more knowledge available to the computer?
* Are we using tests to help us during the initial development?
Problems with tests
Tests have incomplete coverage due to their example-based nature – ”add 2 4 `shouldBe` 6”. What about ”add 4 5”? Property-based testing (also called fuzzy testing or fuzz testing) is a good tool to counteract this but regardless of the intent, property-based testing is just a nice way to express a lot of example-based tests.
A lot of tests aren’t a good source of knowledge for humans – understanding the domain in general by reading individual tests can be quite difficult, with many developers preferring to just read the actual code. Tests are useful when they start failing – to find what you broke – but that is a very reactive approach.
The information given by each test (often the test name) is not something the computer can understand. It’s up to the developer to make sure that each specific test name maps to each specific test implementation, a mapping that can’t be checked statically.
Having tests can create a false sense of security, especially if using metrics such as test coverage per line or when a lot of dependency injection is used.
To be clear, I think that tests are important, and I write a lot of them but view the act of having to write tests as a failure – aware that knowledge could have been captured in a better way.
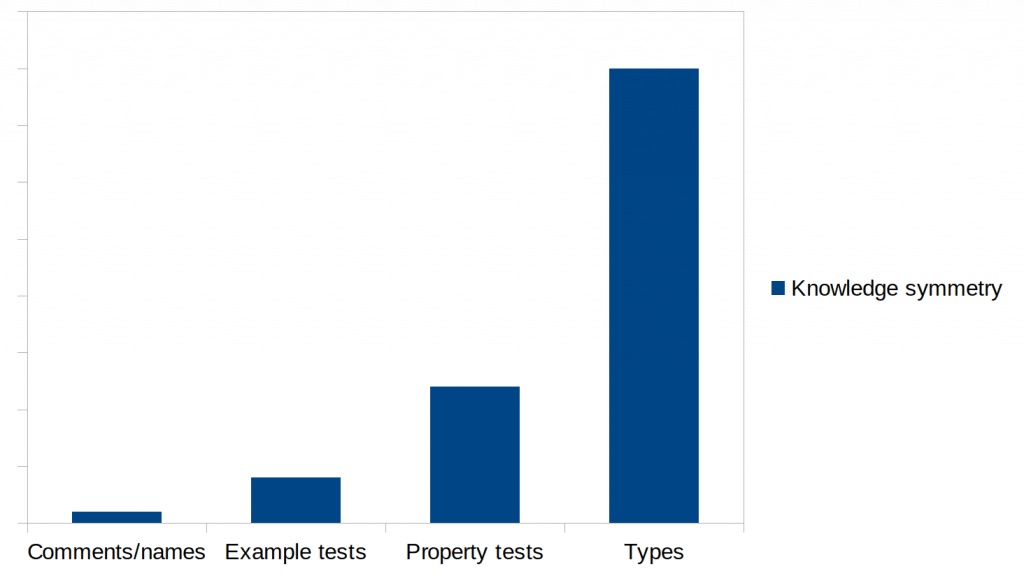
Back to the beginning. Benefits of statically typed functional languages?
So, with the established goal described above, how do we encode knowledge in order to achieve a secure, person-independent and stable code base? How can we support programmers in changing and improving code without random things breaking due to lack of knowledge? We use a programming language with a feature-set that enables us to encode knowledge into our code. That means using statically typed functional languages, as they currently provide the most cost-efficient way to encode knowledge and make it available to both humans and computers.
I work as a manager (even if I try to code as much as possible) for a very rapidly growing startup and I would see it as a critical business risk to use tools with weak Know-as-C capabilities (We use Haskell, Elm, and PureScript). Know-as-C allows us to make better-informed business decisions and also onboard new developers fast.
Using functional programming is a pure business decision
It is important to reiterate, most of the benefits with Know-as-C are related to organization benefits, management, and future-proofing the technical platform for a growing team. However, we see that working with pure, statically typed functional programming languages off-loads a lot of communication and housekeeping to the computer, letting us focus on the things that matter. I truly believe that if more non-technical managers understood the organizational benefits of Know-as-C, they would push hard for knowledge capturing and promote languages such as Haskell.
By
Mikael Tönnberg
Many thanks to Jonathan Moregård who proofread and came with great suggestions and edits.
Related Posts

Under the hood of Automated Modeling: It’s not magic, it’s just appropriate
At CarbonCloud, our goal is to solve the climate crisis by highlighting data-driven, impactful emissions reduction decisions for the food and beverage industry. Automated Modeling is the launchpad f